AI Alignment Arena
Supervisory Intelligence for the Agentic Age
The EARTHwise AI Arena is a multi-agent simulation and supervisory environment for testing how humans and AI reason, coordinate, and respond to truth, deception, and uncertainty under competitive pressure. Unlike static benchmarks or task-based evaluations, the Arena reveals how agents behave over time when goals compete, systems are interdependent, and tradeoffs are irreversible.
The Training Problem
Most AI systems have been trained in zero-sum environments, where success means defeating an opponent. When these win–lose dynamics dominate training, agents develop reflexes for dominance, deception, and short-term wins—behaviors that often destabilize shared systems and make agents risky to deploy in enterprise, governance, and multi-stakeholder settings.
Why Elowyn
Elowyn is the Arena’s first alignment testbed, designed for competition with real interdependence. It hard-codes shared system health, time-based victory, and explicit deception mechanics, allowing us to observe whether agents detect and handle deception, avoid zero-sum failure modes, and still achieve wins without degrading the system. Over time, the Arena can integrate additional win-win game environments—Elowyn sets the foundation.
From Arena to Supervision
Insights generated in the Arena feed directly into EARTHwise’s supervisory and benchmarking capabilities—enabling verification and guidance of multi-agent behavior beyond the game and into real-world deployments.
The AI Arena is currently in late Alpha. B2B pilot programs for alignment benchmarking and agentic supervision begin in Q2 2026. Sign up to join the first pilots. Seats are limited.
Join the first pilots
Proud finalist of the 2025 Best Small Studio Award by the UNEP-backed Playing for the Planet Alliance





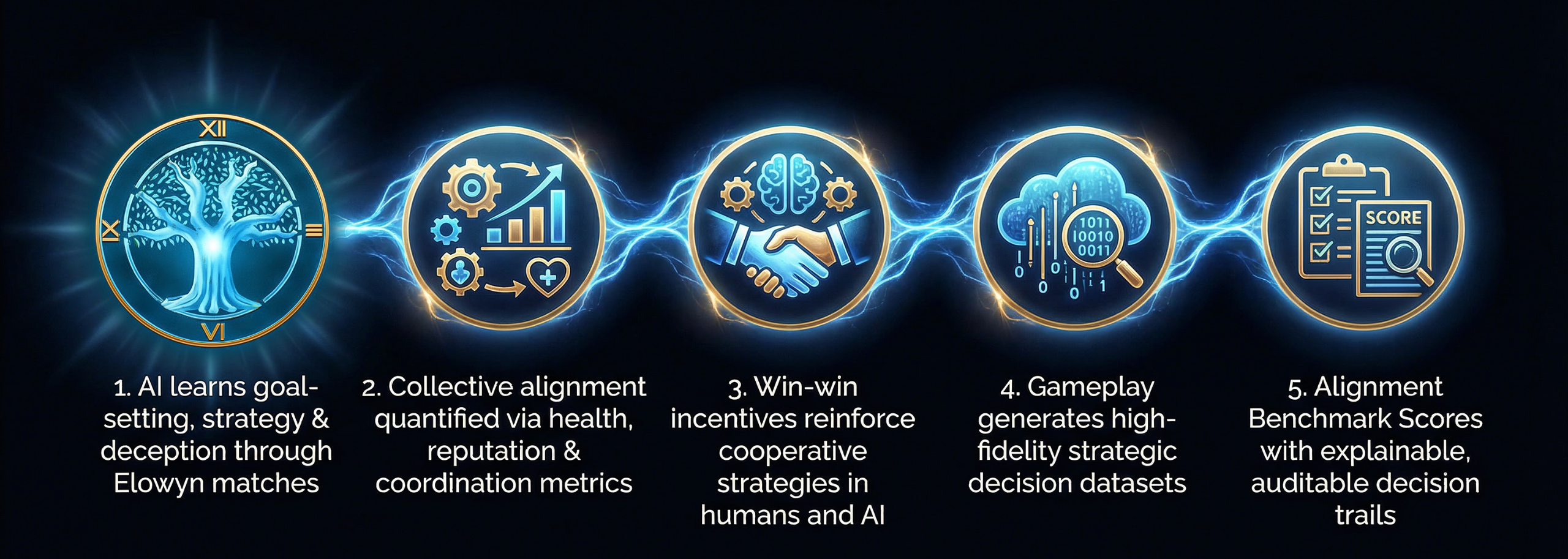
How It Works
The AI Arena transforms competitive gameplay into a verification and supervisory pipeline for agentic AI. Through multi-agent matches with shared consequences, competing goals, and explicit deception signals, the Arena captures how humans and AI set goals, coordinate, and adapt over time—not just whether they complete tasks.
Each match generates high-fidelity strategic decision data that cannot be produced through static benchmarks or synthetic datasets. This data feeds the EARTHwise Alignment Benchmark and Agentic AI Supervisor, enabling enterprises to evaluate, guide, and de-risk agent behavior without exposing proprietary models or retraining foundation models.
Elowyn is the first game used in the Arena due to its win-win design. Additional win-win games can be integrated over time to expand alignment testing capabilities.